
reCAPTCHA, czyli wykorzystanie mocy obliczeniowej ludzkiego umysłu
Każdy użytkownik internetu przynajmniej kilka razy dziennie zmuszony jest przepisywać znaki z obrazka do odpowiedniego pola formularza. Zabezpieczenie to, będące rodzajem CAPTCHA, czyli Completely Automated Public Turing Test to Tell Computers and Humans Apart, chroni systemy informatyczne przy wysyłaniu postów, komentarzy, czy formularzy rejestracji, przed działalnością botów.
W dzisiejszym internecie, pełnym złośliwego oprogramowania, automatycznie wysyłającego nieprzebrane ilości spamu, stosowanie zabezpieczeń jest koniecznością. Około 90% wszystkich wysyłanych maili to niechciana korespondencja, podobnie ma się sprawa także w przypadku komentarzy i postów na forach. Dla przykładu, na moim skromnym blogu na 307 komentarzy użytkowników, przypada 3440 wysłanych spam-postów (91,07%) – w znaczącej części jest to SEO spam, mający poprawiać wyniki określonych stron w wyszukiwarkach.
Stosowanych jest kilka metod, pozwalających odróżnić człowieka, od zautomatyzowanego programu. Niestety, żadna nie jest idealna. Muszą one bowiem łączyć dwie trudne do pogodzenia cechy – wysoką skuteczność, z możliwie niską uciążliwością dla użytkownika. Najpopularniejszą metodą jest zabezpieczenie z kodem ukrytym w obrazku, zwane powszechnie CAPTCHĄ, które wykorzystuje słabości algorytmów automatycznego rozpoznawania tekstu, czyli OCR. Jednakże nie jest ona idealna. Większość stosowanych metod zniekształcenia tekstu nie stanowi trudności dla bardziej zaawansowanych botów, z kolei zbyt duże skomplikowanie powoduje, że z rozwiązaniem ich mają również problemy zwykli użytkownicy. Co gorsza, przepisywanie dziesiątków kodów staje się dla użytkowników po prostu irytujące.
Wedle szacunków, każdego dnia na świecie ludzie rozwiązują około 60 milionów CAPTCHA, za każdym razem pochłania to średnio 10 sekund. O ile w pojedynczym przypadku nie wydaje się to dużym poświęceniem, w skali globalnej oznacza ponad 150.000 godzin ludzkiej pracy marnotrawionych każdego dnia. A gdyby ten wysiłek wykorzystać do czegoś pożytecznego?
Obecnie, aby chronić oraz zapewnić powszechny dostęp do naszego dziedzictwa kulturowego, prowadzone jest wiele projektów digitalizacji książek, które powstały przez erą cyfrową. Wykorzystuje się przy nich techniki OCR, których nawet najlepsze komercyjne algorytmy nie są nieomylne. Co gorsza, wiele starych książek nosi ślady czasu, które często uniemożliwiają wręcz poprawne rozpoznanie pojedynczych liter, lub nawet całych znaków. W takich przypadkach, niezbędna jest pomoc ludzkiego umysłu. Tak właśnie powstała reCAPTCHA.
Idea działania systemu jest prosta. Użytkownikowi zamiast grafiki z ciągiem losowych znaków lub cyfr wysyłane są obrazki zawierające wyrazy, których nie były w stanie poprawnie zidentyfikować algorytmy rozpoznawania tekstu, a z którymi bez większych problemów poradzi sobie ludzki umysł.
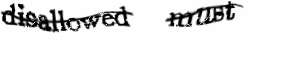
Skąd jednak pewność, że wpisany przez użytkownika wyraz jest poprawny, skoro nie potrafią poradzić z nim sobie algorytmy OCR? Rozwiązanie jest proste. Użytkownik proszony jest o przepisanie dwóch wyrazów z badanego tekstu książki, z który jeden został wcześniej prawidłowo zidentyfikowany przez OCR. Jeżeli wyraz kontrolny został przepisany poprawnie, z dużą pewnością można stwierdzić, iż prawdopodobnie i drugi wyraz jest poprawny. Ludzie jednak są omylni, zatem aby mieć pewność, każdy wyraz można wysłać na przykład do 10 różnych osób.
Czy projekt ten odniesie sukces? Wszystko zależy od twórców stron, którzy muszą się przekonać do umieszczenia na swoich witrynach zmodyfikowanych kodów. Sposób ten oczywiście nie uwolni internautów od żmudnego przepisywania obrazków, jednak może sprawić, że ta irytująca czynność nabierze nowego wymiaru. Zawsze dobrze mieć świadomość, że nasza praca, nawet ta najdrobniejsza, nie pójdzie na marne;)
 Witam wszystkich na moim blogu. Na wstępie kilka słów wyjaśnienia. Nie jest to typowy blog, w którym notki pojawiają się regularnie, kilka razy w tygodniu. Z bardzo prozaicznej przyczyny. Nie mam po prostu czasu na częste aktualizacje, a nie chciałbym też pisać, dla samego pisania, by zapełnić pustą przestrzeń. Takich miejsc znajdziecie w Sieci tysiące.
Chciałbym wzamian zachęcić do przeczytania najpopularniejszych oraz najciekawszych tekstów archiwalnych:
Witam wszystkich na moim blogu. Na wstępie kilka słów wyjaśnienia. Nie jest to typowy blog, w którym notki pojawiają się regularnie, kilka razy w tygodniu. Z bardzo prozaicznej przyczyny. Nie mam po prostu czasu na częste aktualizacje, a nie chciałbym też pisać, dla samego pisania, by zapełnić pustą przestrzeń. Takich miejsc znajdziecie w Sieci tysiące.
Chciałbym wzamian zachęcić do przeczytania najpopularniejszych oraz najciekawszych tekstów archiwalnych:
Ciekawa sprawa…a gdyby tak ludzie powiedzmy 0.5 mln internautów
zaprząc do łamania prawdziwych kodów? Zakręcone to wszystko ponieważ okazuje się, że zsieciowanie nas wszystkich otwiera wile nowych “funkcjonalności” a zarazem i zagrożeń ;)
pozdr.
Witam,
wspomnę może tylko, że istnieją alternatywne metody weryfikacji użytkowników poprzez poproszenie go o wykonanie opisanej słownie czynności, np. pomnożenie dwóch losowych wartości i podanie wyniku tego mnożenia. W przypadku takiego mechanizmu zaimplementowanego w języku polskim, skrypt spamera ma nie lada orzeszek :)
pozdrawiam!
Pingback: Steve Fossett poszukiwany również w Internecie - Piotr Jaczewski